
解读 | GreatDB如何进行数据分布?
2022.07.29为什么要使用分布式数据库?
原因在于,当数据量增长到一定程度,查询或操作效率逐步降低时,传统集中式的单节点存储、单点计算的数据存储和算力瓶颈明显。需要通过借助中间件或路由分片的方式,将数据按照一定规则做横向的扩展。随着业务的不断扩容和发展,单点计算便逐步演变为分布式数据库多点计算的方式,以提升业务处理能力的响应速度。
分布式数据库使用分区表或交叉分布式表来进行数据分布。在数据存储和计算方面,将集中式的单节点计算转化为多节点存储和多节点运算的模式。在数据分布方面,通过内部分片路由算法和规则,将数据打散分布在多个实例或主机上,计算层执行SQL路由解析。满足条件的数据只存储在某个分区上,只需单点响应计算,无需扫描全表,因此可以极大提升检索精准度。计算节点根据分片路由自动从表中排除不符合条件的分区。分布式数据库采用多点分布计算存储数据,正是最大化强化分区裁剪和分片计算的能力。
接下来,我们看看GreatDB分布式数据库是如何来进行数据分布的。
GreatDB支持的数据分片方式如下:
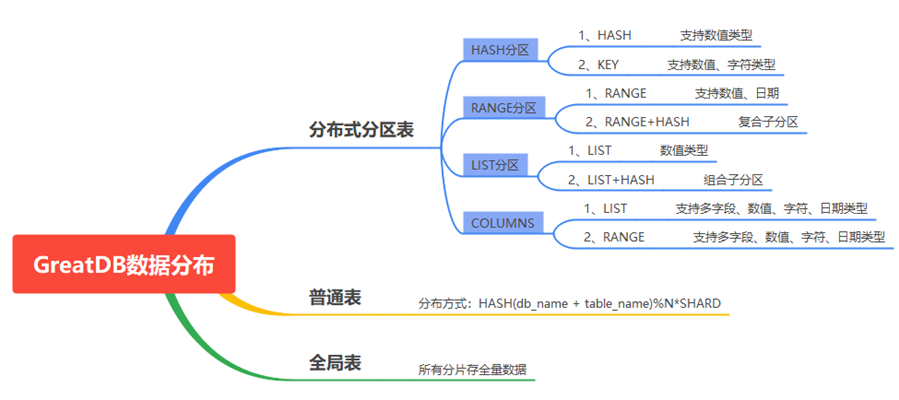
编辑
分布式表 (分区表)
GreatDB分区表的分布策略较为复杂,内部采用的是线性哈希(linear hash)的算法。shard分片数表示hash桶的数量,分片id 表示hash 值。采用线性哈希算法的好处在于扩缩容情况下,可保持分片规则的稳定性,减少分布式事务。另外,GreatDB的分片在计算节点上,相对业内采用“元数据管理节点”或者“K-VALUES”更新表的元数据分片信息,其优势在于能将数据相对均匀地分散在后端存储节点上,更易发挥分布式数据库多点多实例计算的性能。
下面简单列举一下分布式数据库中,常用表类型的特点。
1)hash分区表:一般针对主键列或唯一性约束的数值类型的列,这样通过hash算法使数据散列程度更高,数据相对分布更均匀。GreatDB支持无主键、无唯一性索引表的创建,后端内部通过增加隐藏字段hidden_pk来保证数据的唯一和快速定位。访问后端shard分片信息如下:
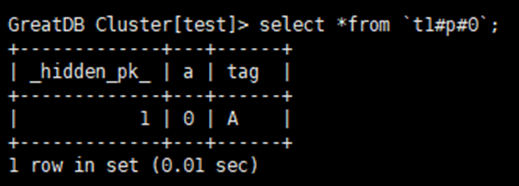
编辑
2)GreatDB分布式有如下两种计算方式,根据hash分区数和shard分片个数进行自适应算法匹配:
shard=HASH(ID)%N*shard 或 shard=HASH(ID)%(N*shard/2)
GreatDB HASH分片:
create table t1(id bigint primary key, name varchar2 (20)) partition by hash(id) partitions 8;
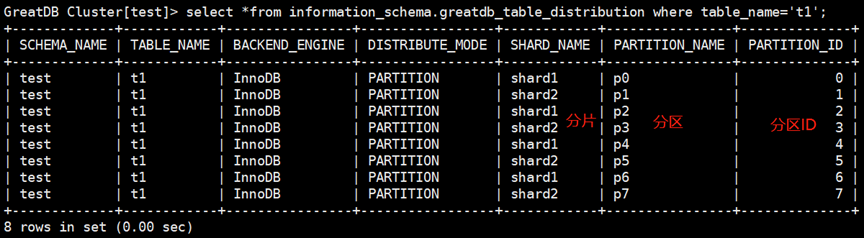
编辑
GreatDB 非数值类型字段作为分片时,采用key算法SQL如下:
create table t2(id char(20) primary key, name varchar2 (20)) partition by key(id) partitions 8;
GreatDB冷热数据迁移分类:
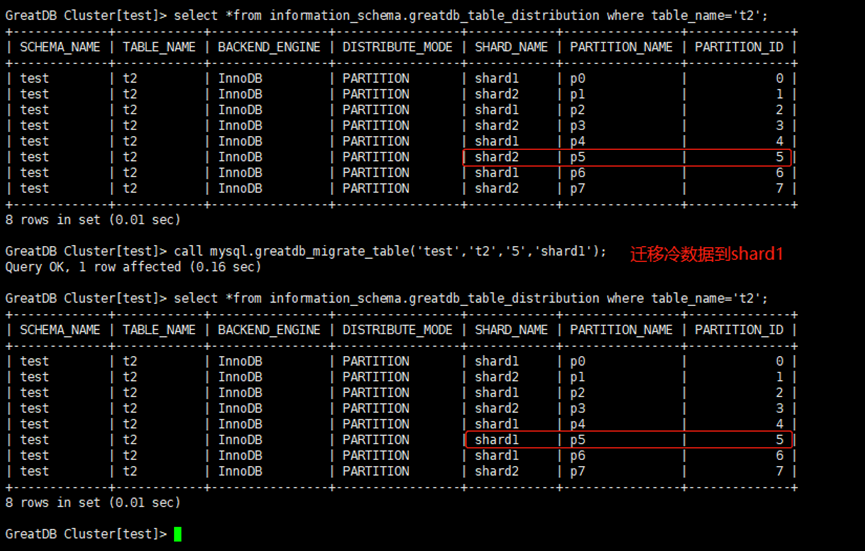
编辑
描述:优势是完全兼容MySQL语法,最大支持8192个hash分区。每个shard分片中存储分区表部分partition。支持DML操作跨分片的操作,可以像使用单机MySQL数据库一样使用GreatDB。整合原始MySQL业务可做到无缝迁移到GreatDB中,对业务对DBA更友好。
2)range分区表:一般用于数值或日期类型的范围划分,或根据时间做数据划分。示例SQL及各产品的语法差异如下:
GreatDB RANGE分区语法:
create table range_tab ( f1 bigint, f2 varchar(20), f3 varchar(20) ) partition by range (f1) ( partition p0 values less than (100), partition p1 values less than (200) );
冷热分区迁移:
编辑
描述:GreatDB 对原生MySQL语法完全兼容。根据业务指定分区范围字段设置分区范围值即可,可直接针对分区进行增加、删除、截断等操作,DML操作命令与MySQL一致;支持冷热数据分片存储,可按需将冷热数据分区分类迁移到不同的shard分片,且迁移是一键式方式较为便捷高效。
普通表
GreatDB 普通表:
create table normal1(c1 int primary key, c2 int) ;

编辑
GreatDB(分布式部署)根据hash(库名+表名)/shard 随机分配到任一分片节点,并可根据需求手动迁移普通表到不同分片;
全局表/复制表
GreatDB :
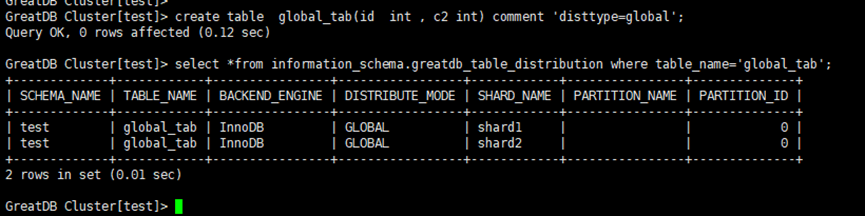
create table global_tab( id int , c2 int ) comment 'disttype=global'; --关键词 "disttype=global"
编辑
适用场景:
全局表或者叫复制表,其作用多用于业务层的配置表或关联查询的静态表。如网站商品的标签表、类别表。目的是优化分布式的下推和后端存储数据的内部计算,减少跨节点的数据交互和分布式事务开销,提升SQL的查询效率和性能。为了提升分布式表跨节点关联查询的性能,而创建的业务配置表,静态表,或极少更新的表,不建议大表使用全局表,其副本冗余较多,磁盘空间占用较大大,更新性能代价大。
“
相较市面上其他主流的国产分布式数据库,GreatDB分布式数据库具有如下特点:
1、采用多种分片计算方式:数据分布上采用多种分片计算方式,且路由分片信息集成在计算层数据字典表中,支持8种数据分布方式;
2、数据分布路由表集成度高:表数据分布路由上,GreatDB分布式没有中间层shard map分区映射层,其数据分布路由表以字典形式存在计算层,集成度高。其它产品shard map层的路由分片方式大多存储在独立的元数据管理实例或节点,或缓存在键值型库内频繁读取调用,虽在数据分布散列程度上更好,粒度更细,但可能在分片路由映射维护和更新消耗上更大;
3、支持数据跨片更新及跨分片迁移:支持时间范围分区的冷热数据归类迁移。在涉及跨分片或更新分片字段时,GreatDB对前端用户透明,无需先删除再插入的处理方式,正常DML操作即可,无任何限制。且SQL语法无过多SQL前缀、后缀等晦涩难懂的语法变体,从DBA使用习惯和MySQL生态上来说更友好。
